- Leading Netty effort at Red Hat
- Vert.x / NIO / Performance
- Author of Netty in Action
- @normanmaurer
- github.com/normanmaurer
Loop unrolling
- JIT may unroll loops
- eliminate branching

https://www.flickr.com/photos/st3f4n/3805014022/
https://www.flickr.com/photos/st3f4n/3805014022/
May be hard for the JIT to unrollint i = 0;
for (;;) {
if (array.length == i) {
break;
}
doSomething(array[i++]);
}array.length == 4
Easy to unrollint i = 0;
for (int i = 0; i < array.length; i++) {
doSomething(array[i]);
}unrolled loopdoSomething(array[0]);
doSomething(array[1]);
doSomething(array[2]);
doSomething(array[3]);| Limit for inline hot methods is 325 byte operations per default… |
Before inlinedpublic void methodA() {
... // Do some work A (1)
methodB();
}
private void methodB() {
... // Do some more work B (2)
}methodB is inlined into methodApublic void methodA() {
... // Do some work A (3)
... // Do some more work B (4)
}Record inline tasksjava \
-XX:+PrintCompilation \ (1)
-XX:+UnlockDiagnosticVMOptions \ (2)
-XX:+PrintInlining \ (3)
.... > inline.log| 1 | Prints out when JIT compilation happens |
| 2 | Is needed to use flags like -XX:+PrintInlining |
| 3 | Prints what methods were inlined |
inline.log content example@ 42 io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe::read (191 bytes) inline (hot) (1)
@ 42 io.netty.channel.nio.AbstractNioMessageChannel$NioMessageUnsafe::read (327 bytes) hot method too big (2)
@ 4 io.netty.channel.socket.nio.NioSocketChannel::config (5 bytes) inline (hot)
@ 1 io.netty.channel.socket.nio.NioSocketChannel::config (5 bytes) inline (hot)
@ 12 io.netty.channel.AbstractChannel::pipeline (5 bytes) inline (hot)| 1 | Method is hot and was inlined |
| 2 | Method is hot and was too big for inlining :( |
| You want to have your hot methods inlined, for max performance when possible! |
Original code which was cause of too big for inliningprivate final class NioMessageUnsafe extends AbstractNioUnsafe {
public void read() {
final SelectionKey key = selectionKey();
if (!config().isAutoRead()) {
int interestOps = key.interestOps();
if ((interestOps & readInterestOp) != 0) {
// only remove readInterestOp if needed
key.interestOps(interestOps & ~readInterestOp);
}
}
... // rest of the method
}
...
}Factor out less likely branch out in new methodprivate final class NioMessageUnsafe extends AbstractNioUnsafe {
private void removeReadOp() {
SelectionKey key = selectionKey();
int interestOps = key.interestOps();
if ((interestOps & readInterestOp) != 0) {
// only remove readInterestOp if needed
key.interestOps(interestOps & ~readInterestOp);
}
}
public void read() {
if (!config().isAutoRead()) {
removeReadOp();
}
... // rest of the method
}
...
}inline.log content after change@ 42 io.netty.channel.nio.AbstractNioMessageChannel$NioMessageUnsafe::read (288 bytes) inline (hot) (1)| 1 | Method is now small enough for inlining :) |

https://www.flickr.com/photos/brears/2685223351
http://www.cliffc.org/blog/2007/11/06/clone-or-not-clone/
| You can inline by hand |

https://www.flickr.com/photos/tracheotomy_bob/5430166369
| Only do this if you really need the last percent of performance. This can result in a maintainance nightmare! |

https://www.flickr.com/photos/stavos52093/13807616194/
Ouch :(public class YourClass {
@Override
public void finalize() {
// cleanup resources and destroy them
}
}Better :)public class YourClass {
public void destroy() {
// cleanup resources and destroy them
}
}| Overriding finalize() is 99% of the time a very bad idea! |

https://www.flickr.com/photos/counteragent/2190576349

https://www.flickr.com/photos/tracheotomy_bob/5430166369
| Also pre-fetch works out quite well for array based datastructures, also cache lines etc. |
Roll your own linked-list datastructurepublic class Entry {
Entry next; (1)
Entry prev;
public void methodA() {}
}
public class EntryList {
Entry head; (2)
Entry tail;
public void add(Entry entry) {}
}| 1 | Entry itself can be used as node |
| 2 | head and tail of the list |
| Each Entry can hold be added to one EntryList. |

https://www.flickr.com/photos/ryanr/142455033/
There is @Contended in Java8 but needs to be enabled via switch and not allow to pack multiple objects in one cache-line. This is part of JEP-142 |
| The following code snippets and diagram is based on Martin Thompsons blog posts False Sharing and False Sharing && Java 7. |
https://twitter.com/normanmaurer/status/465821479012401152
| Credit where credit is due. |
False-sharing Testpublic final class FalseSharing implements Runnable {
private static AtomicLong[] longs = new AtomicLong[NUM_THREADS];
....
public static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
threads[i] = new Thread(new FalseSharing(i));
for (Thread t : threads) { t.start(); }
for (Thread t : threads) { t.join(); }
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) { longs[arrayIndex].set(i); }
}
}AtomicLong without paddingpublic final class FalseSharing implements Runnable {
private static AtomicLong[] longs = new AtomicLong[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new AtomicLong();
}
}
...
}AtomicLong with paddingpublic final class FalseSharing implements Runnable {
private static PaddedAtomicLong[] longs = new PaddedAtomicLong[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new PaddedAtomicLong();
}
}
...
public static long sumPaddingToPreventOptimisation(final int index) {
PaddedAtomicLong v = longs[index];
return v.p1 + v.p2 + v.p3 + v.p4 + v.p5 + v.p6;
}
public static class PaddedAtomicLong extends AtomicLong {
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
}
}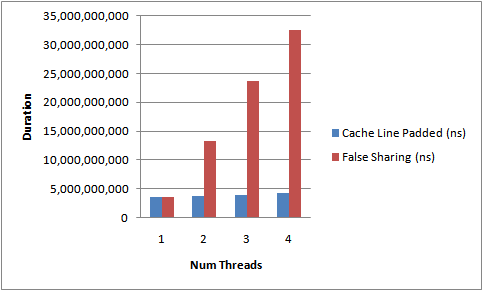
http://mechanical-sympathy.blogspot.de/2011/07/false-sharing.html
public static Unsafe getUnsafe() {
Class cc = sun.reflect.Reflection.getCallerClass(2);
if (cc.getClassLoader() != null)
throw new SecurityException("Unsafe");
return theUnsafe;
}
https://www.flickr.com/photos/oldpatterns/6100020538
| Can do a lot of things faster then abstractions because of eliminate range checks and allow to access stuff directly via memory addresses etc. |
Caution: @lagergren may hunt you down ;)

http://zeroturnaround.com/rebellabs/dangerous-code-how-to-be-unsafe-with-java-classes-objects-in-memory/
| SPSC ⇒ Single Producer Single Consumer |
| SPMC ⇒ Single Producer Multi Consumer |
| MPSC ⇒ Multi Producer Single Consumer |
| MPMC ⇒ Multi Producer Multi Consumer |
| Usage pattern is imprtant! |
| All concurrent queues in the JDK are MPMC |

https://www.flickr.com/photos/kirisryche/4350193154
| JAQ-InABox provides some nice alternatives. Say thanks to @nitsanw. |
| Cheap volatile writes, we all love cheap when it comes to performance! |

https://www.flickr.com/photos/vmabney/9431857312
| Only works for Single Writers a.k.a Single Producers. More details on Atomic*.lazySet is a performance win for single writers post by @nitsanw. |
Slow nextIdx(…) method based on modulo operationprivate final Object[] array = new Object[128];
private int nextIdx(int index) {
return (index + 1) % array.length;
}Fast nextIdx(…) method based on bitwise operationprivate final Object[] array = new Object[128];
private final int mask = array.length - 1;
private int nextIdx(int index) {
return (index + 1) & mask;
}| Bitwise operations are most of the times faster then Arithmetic. |
| Only works for Single Writers a.k.a Single Producers. More details on Atomic*.lazySet is a performance win for single writers post by @nitsanw. |

https://www.flickr.com/photos/dolmansaxlil/5347064183
| Slides generated with Asciidoctor and DZSlides backend |
| Original slide template - Dan Allen & Sarah White |
All pictures licensed with Creative Commons Attribution orCreative Commons Attribution-Share Alike |