- HTTP / Pipelining
- Writing gracefully
- Buffers best-practises
- EventLoop
Use Pooling of buffers to reduce allocation / deallocation time!
| Pooling pays off for direct and heap buffers! |
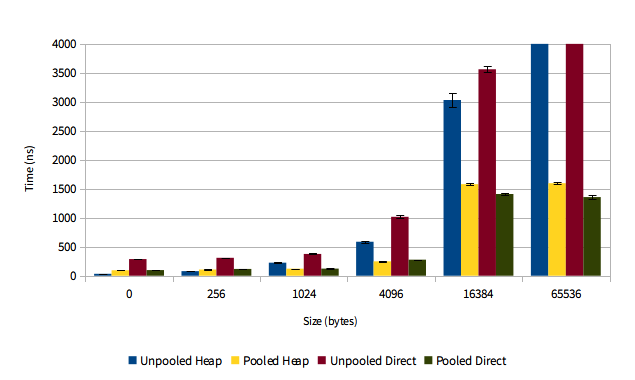
https://blog.twitter.com/2013/netty-4-at-twitter-reduced-gc-overhead



